Understanding Reasoning LLMsMethods and Strategies for Building and Refining Reasoning Models by Sebastian Raschka
- Matvei Kudelin
- Mar 16
- 7 min read
This article describes the four main approaches to building reasoning models, or how we can enhance LLMs with reasoning capabilities. I hope this provides valuable insights and helps you navigate the rapidly evolving literature and hype surrounding this topic.
In 2024, the LLM field saw increasing specialization. Beyond pre-training and fine-tuning, we witnessed the rise of specialized applications, from RAGs to code assistants. I expect this trend to accelerate in 2025, with an even greater emphasis on domain- and application-specific optimizations (i.e., "specializations").
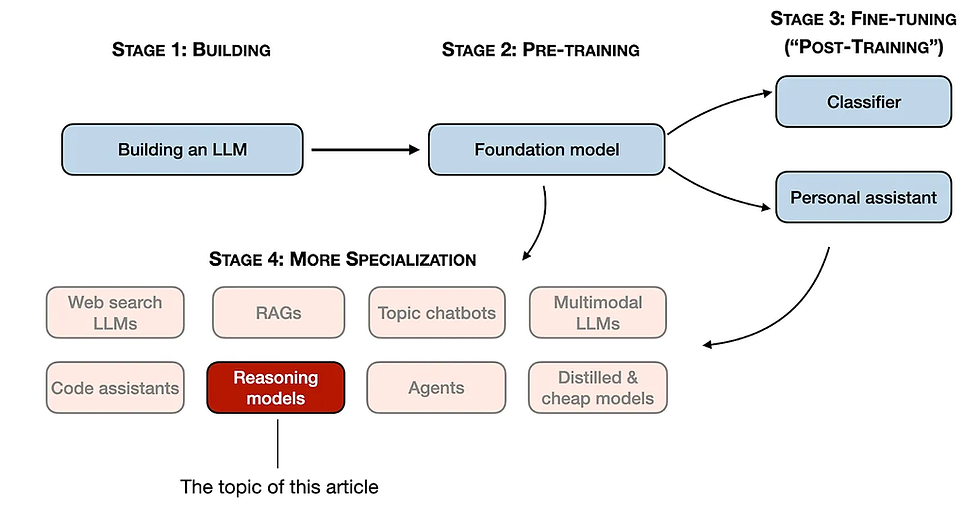
The development of reasoning models is one of these specializations. This means we refine LLMs to excel at complex tasks that are best solved with intermediate steps, such as puzzles, advanced math, and coding challenges. However, this specialization does not replace other LLM applications. Because transforming an LLM into a reasoning model also introduces certain drawbacks, which I will discuss later.
To give you a brief glimpse of what's covered below, in this article, I will:
Explain the meaning of "reasoning model"
Discuss the advantages and disadvantages of reasoning models
Outline the methodology behind DeepSeek R1
Describe the four main approaches to building and improving reasoning models
Share thoughts on the LLM landscape following the DeepSeek V3 and R1 releases
Provide tips for developing reasoning models on a tight budget
I hope you find this article useful as AI continues its rapid development this year!
How do we define "reasoning model"?
If you work in AI (or machine learning in general), you are probably familiar with vague and hotly debated definitions. The term "reasoning models" is no exception. Eventually, someone will define it formally in a paper, only for it to be redefined in the next, and so on.
In this article, I define "reasoning" as the process of answering questions that require complex, multi-step generation with intermediate steps. For example, factual question-answering like "What is the capital of France?" does not involve reasoning. In contrast, a question like "If a train is moving at 60 mph and travels for 3 hours, how far does it go?" requires some simple reasoning. For instance, it requires recognizing the relationship between distance, speed, and time before arriving at the answer.

Most modern LLMs are capable of basic reasoning and can answer questions like, "If a train is moving at 60 mph and travels for 3 hours, how far does it go?" So, today, when we refer to reasoning models, we typically mean LLMs that excel at more complex reasoning tasks, such as solving puzzles, riddles, and mathematical proofs.
Additionally, most LLMs branded as reasoning models today include a "thought" or "thinking" process as part of their response. Whether and how an LLM actually "thinks" is a separate discussion.
Intermediate steps in reasoning models can appear in two ways. First, they may be explicitly included in the response, as shown in the previous figure. Second, some reasoning LLMs, such as OpenAI's o1, run multiple iterations with intermediate steps that are not shown to the user.

When should we use reasoning models?
Now that we have defined reasoning models, we can move on to the more interesting part: how to build and improve LLMs for reasoning tasks. However, before diving into the technical details, it is important to consider when reasoning models are actually needed.
When do we need a reasoning model? Reasoning models are designed to be good at complex tasks such as solving puzzles, advanced math problems, and challenging coding tasks. However, they are not necessary for simpler tasks like summarization, translation, or knowledge-based question answering. In fact, using reasoning models for everything can be inefficient and expensive. For instance, reasoning models are typically more expensive to use, more verbose, and sometimes more prone to errors due to "overthinking." Also here the simple rule applies: Use the right tool (or type of LLM) for the task.
The key strengths and limitations of reasoning models are summarized in the figure below.

A brief look at the DeepSeek training pipeline
Before discussing four main approaches to building and improving reasoning models in the next section, I want to briefly outline the DeepSeek R1 pipeline, as described in the DeepSeek R1 technical report. This report serves as both an interesting case study and a blueprint for developing reasoning LLMs.
Note that DeepSeek did not release a single R1 reasoning model but instead introduced three distinct variants: DeepSeek-R1-Zero, DeepSeek-R1, and DeepSeek-R1-Distill.
Based on the descriptions in the technical report, I have summarized the development process of these models in the diagram below.

Next, let's briefly go over the process shown in the diagram above. More details will be covered in the next section, where we discuss the four main approaches to building and improving reasoning models.
(1) DeepSeek-R1-Zero: This model is based on the 671B pre-trained DeepSeek-V3 base model released in December 2024. The research team trained it using reinforcement learning (RL) with two types of rewards. This approach is referred to as "cold start" training because it did not include a supervised fine-tuning (SFT) step, which is typically part of reinforcement learning with human feedback (RLHF).
(2) DeepSeek-R1: This is DeepSeek's flagship reasoning model, built upon DeepSeek-R1-Zero. The team further refined it with additional SFT stages and further RL training, improving upon the "cold-started" R1-Zero model.
(3) DeepSeek-R1-Distill*: Using the SFT data generated in the previous steps, the DeepSeek team fine-tuned Qwen and Llama models to enhance their reasoning abilities. While not distillation in the traditional sense, this process involved training smaller models (Llama 8B and 70B, and Qwen 1.5B–30B) on outputs from the larger DeepSeek-R1 671B model.
1) Inference-time scaling
One way to improve an LLM's reasoning capabilities (or any capability in general) is inference-time scaling. This term can have multiple meanings, but in this context, it refers to increasing computational resources during inference to improve output quality.
A rough analogy is how humans tend to generate better responses when given more time to think through complex problems. Similarly, we can apply techniques that encourage the LLM to "think" more while generating an answer. (Although, whether LLMs actually "think" is a different discussion.)
One straightforward approach to inference-time scaling is clever prompt engineering. A classic example is chain-of-thought (CoT) prompting, where phrases like "think step by step" are included in the input prompt. This encourages the model to generate intermediate reasoning steps rather than jumping directly to the final answer, which can often (but not always) lead to more accurate results on more complex problems. (Note that it doesn't make sense to employ this strategy for simpler knowledge-based questions, like "What is the capital of France", which is again a good rule of thumb to find out whether a reasoning model makes sense on your given input query.)

The aforementioned CoT approach can be seen as inference-time scaling because it makes inference more expensive through generating more output tokens.
Another approach to inference-time scaling is the use of voting and search strategies. One simple example is majority voting where we have the LLM generate multiple answers, and we select the correct answer by majority vote. Similarly, we can use beam search and other search algorithms to generate better responses.
I highly recommend the Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters paper that I described in my previous Noteworthy AI Research Papers of 2024 (Part Two) article (https://magazine.sebastianraschka.com/p/ai-research-papers-2024-part-2) for more details on these different strategies.

The DeepSeek R1 technical report categorizes common inference-time scaling methods (such as Process Reward Model-based and Monte Carlo Tree Search-based approaches) under "unsuccessful attempts." This suggests that DeepSeek did not explicitly use these techniques beyond the R1 model's natural tendency to generate longer responses, which serves as an implicit form of inference-time scaling compared to the V3 base model.
However, explicit inference-time scaling is often implemented at the application layer rather than within the LLM itself, so DeepSeek may still apply such techniques within their app.
I suspect that OpenAI's o1 and o3 models use inference-time scaling, which would explain why they are relatively expensive compared to models like GPT-4o. In addition to inference-time scaling, o1 and o3 were likely trained using RL pipelines similar to those used for DeepSeek R1. More on reinforcement learning in the next two sections below.
2) Pure reinforcement learning (RL)
One of my personal highlights from the DeepSeek R1 paper is their discovery that reasoning emerges as a behavior from pure reinforcement learning (RL). Let's explore what this means in more detail.
As outlined earlier, DeepSeek developed three types of R1 models. The first, DeepSeek-R1-Zero, was built on top of the DeepSeek-V3 base model, a standard pre-trained LLM they released in December 2024. Unlike typical RL pipelines, where supervised fine-tuning (SFT) is applied before RL, DeepSeek-R1-Zero was trained exclusively with reinforcement learning without an initial SFT stage as highlighted in the diagram below.

Still, this RL process is similar to the commonly used RLHF approach, which is typically applied to preference-tune LLMs. (I covered RLHF in more detail in my article, LLM Training: RLHF and Its Alternatives.) However, as mentioned above, the key difference in DeepSeek-R1-Zero is that they skipped the supervised fine-tuning (SFT) stage for instruction tuning. This is why they refer to it as "pure" RL. (Although, RL in the context of LLMs differs significantly from traditional RL, which is a topic for another time.)
For rewards, instead of using a reward model trained on human preferences, they employed two types of rewards: an accuracy reward and a format reward.
The accuracy reward uses the LeetCode compiler to verify coding answers and a deterministic system to evaluate mathematical responses.
The format reward relies on an LLM judge to ensure responses follow the expected format, such as placing reasoning steps inside <think> tags.
Surprisingly, this approach was enough for the LLM to develop basic reasoning skills. The researchers observed an "Aha!" moment, where the model began generating reasoning traces as part of its responses despite not being explicitly trained to do so, as shown in the figure below.

While R1-Zero is not a top-performing reasoning model, it does demonstrate reasoning capabilities by generating intermediate "thinking" steps, as shown in the figure above. This confirms that it is possible to develop a reasoning model using pure RL, and the DeepSeek team was the first to demonstrate (or at least publish) this approach.
You can continue reading the article at the source of it:
Comments